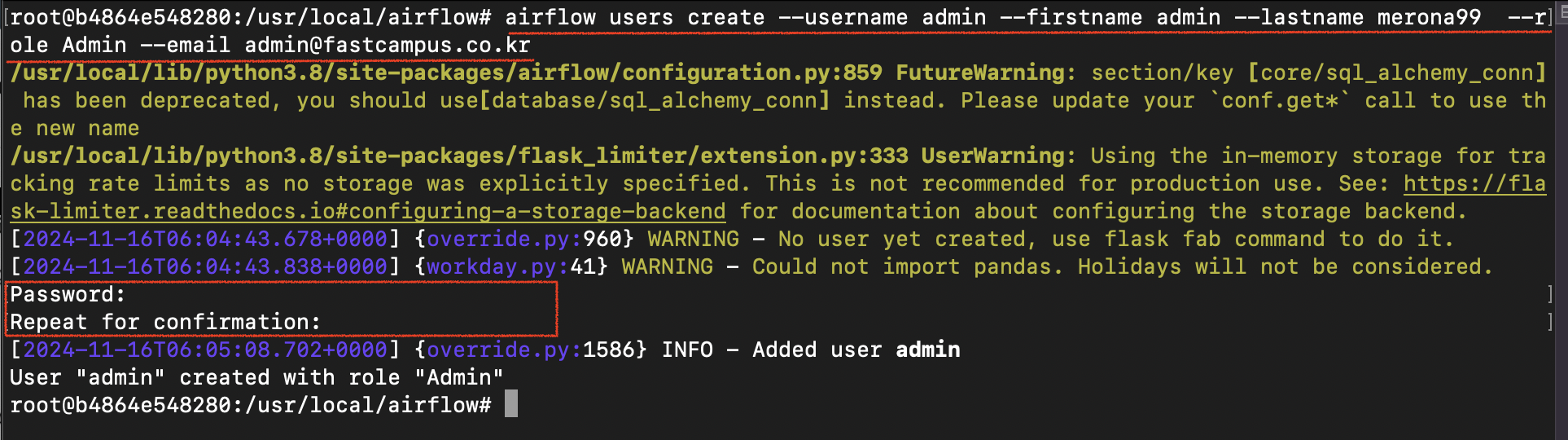
설정했던 id와 pw(admin / admin)를 입력하면 로그인이 되면서 위 화면이 나타난다.
홈 화면에 보이는 모든 목록들은 Airflow 예제들이다.
아무거나 하나를 클릭해서 들어가보자.
이렇게 해당 Dag의 상세정보를 확인할 수 있고,
해당 Dag의 flow를 확인할 수도 있다.
3. Airflow에서 Dag 란?
DAG의 정의
DAG (Directed Acyclic Graph)이며 Airflow에서 워크플로우를 정의하는 주요 구성 요소. DAG는 방향성을 가진 비순환 그래프이며, 여러 작업(Task)들과 이들 간의 의존성을 나타냄
작업(Task): DAG 내에서 실행되는 개별 단위. ex) 데이터 다운로드, 변환/모델 학습 등을 작업
의존성(Dependency): 한 작업이 다른 작업에 의존하는 관계를 의미 ex) 데이터 변환 작업을 데이터 다운로드 작업이 완료된 후에 실행되야 함
Python 스크립트로 정의
DAG의 구성 요소
Operator: Airflow에서 작업을 수행하는 객체. 다양한 유형의 Operator가 있으며, 각 특정 작업을 수행
Task: Operator의 인스턴스로 DAG 내에서 실행되는 개별 작업을 나타냄
Task Instance: 특정 시점에서 Task의 실행 인스턴스
Workflow: 전체적인 작업의 흐름을 나타내며, 하나 이상의 DAG로 구성
작업 순서 및 의존성 설정
작업 순서와 의존성은 DAG 내에서 >> 또는 << 연산자를 사용하여 정의
# task1이 task2보다 먼저 실행되도록 설정
task1 >> task2
DAG 주의 사항
의존성 순환: DAG에서는 순환 의존성을 가질 수 없음. 즉, 어떤 작업도 직접적이거나 간접적으로 자기 자신에게 의존할 수 없음
스케줄링: 'start_date'와 'schedule_interval'을 적절히 설정하여 작업이 예상대로 실행되도록 해야함
오류 처리: 각 Task는 실패 할 수 있으므로, 오류 처리 로직을 고려해야함
4. 실습
4-1) Hello Airflow DAG 실습
Hello Airflow DAG Docker Container
[실습순서]
1단계 : dag 작성
2단계 : dag 실행
3단계 : dag 실행 결과 확인
처음 실습으로 "hello airflow dag. I'm merona99! we can do it."과 같은 문장이 있을 때, 단어별로 순차적으로 출력하는 dag를 생성해보자.
task가 여러개 있고, 각각은 python operator로 구성되어있고 출력해주도록 만들어보자.
[경로]
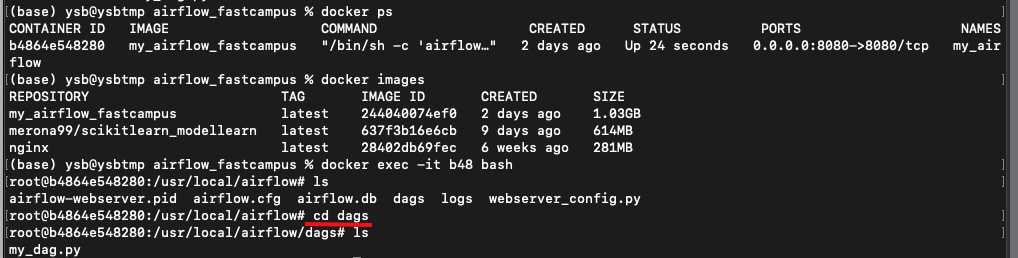
airflow docker안으로 진입해서 dag라는 경로로 가주자.
이곳에 우리의 hello dag를 만들어 볼 것이다.
[hello DAG 생성]
vim hello_airflow_dag.py
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
# DAG 정의
default_args = {
'owner': 'airflow',
'depends_on_past': False, # 과거에 dependence가 있는지
'start_date': datetime(2023, 11, 25),
'email_on_failure': False, # email로 실패여부 보낸건지
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5), # 특정 workflow가 잘못됬을시 5분뒤 재실행
}
dag = DAG(
'hello_airflow_dag',
default_args=default_args,
description='A simple tutorial DAG',
schedule_interval=timedelta(days=1), # 하루 한번 스케줄링 실행
)
# 출력 함수 정의
def print_word(word):
print(word)
# 문장
sentence = "hello airflow dag. fast campus lecture! we can do it."
# 각 단어를 순차적으로 출력하는 Task 생성
prev_task = None
for i, word in enumerate(sentence.split()):
task = PythonOperator(
task_id=f'print_word_{i}',
python_callable=print_word,
op_kwargs={'word': word},
dag=dag,
)
if prev_task:
prev_task >> task
prev_task = task
이후 sync를 한번 쳐준 후
sync
reserialize를 진행한다.
airflow dags reserialize
[airflow 서버에서 확인]
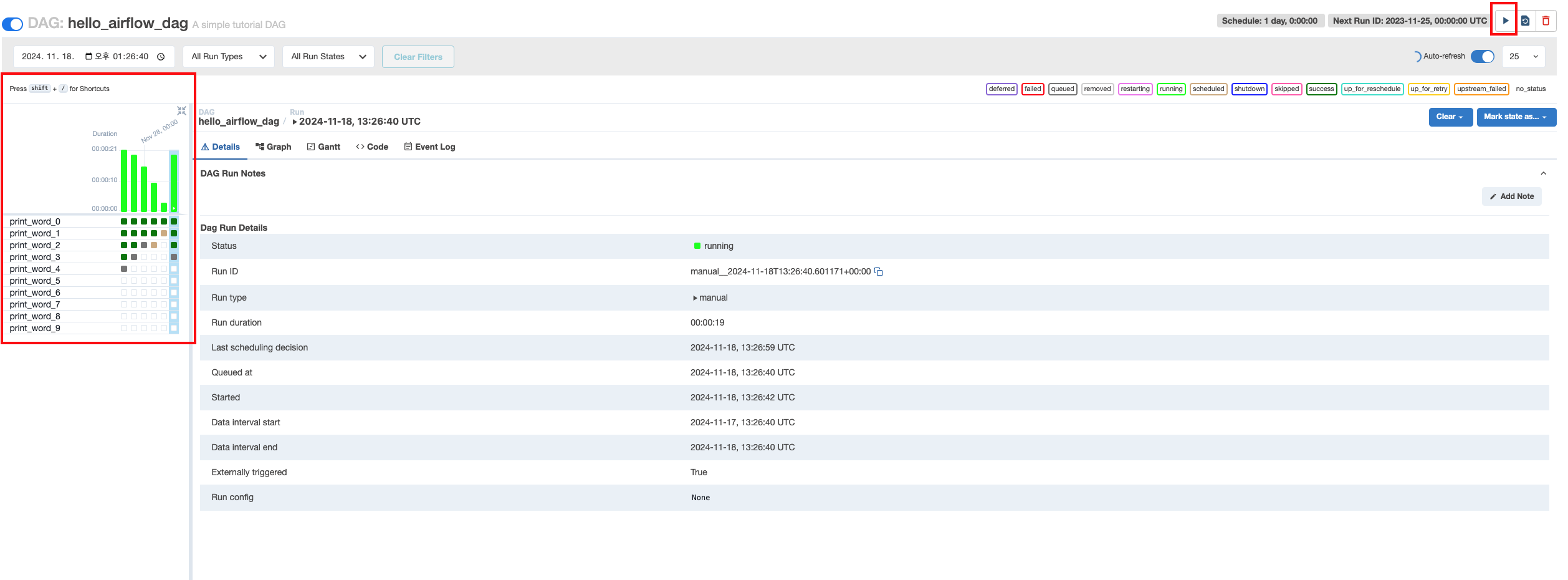
그러면 이렇게 airflow서버에서 내가 만들었던 hello_airflow_dag가 나타난다.
owner도 설정해줬던 airflow로 잘 나오고,
startday도 지정한 날로부터 1Day만큼 스케줄러가 돌도록 잘 설정된 것을 확인할 수 있다.
[graph]
총 10개의 python operator가 생성됬다.
아까 설정했던 문장이 총 10개의 단어로 쪼개지기 때문이다.
[DAG 실행]
화면에서 상단 우측에 있는 화살표 버튼을 클릭하면 된다.
[DAG 실행되는 화면]
상단 좌측을보면 실행되는 모습이 보인다.
[하나의 task 선택]
해당 task를 마우스로 클릭하면 된다.
[출력확인]
Logs탭을 눌러보면 첫 단어였던 hello가 잘 출력된 것이 보인다.
❗️주의할 점 특정 dag를 실행할 때, 지정했던 start_date부터 실행이 된다. 즉 위에 작성했던 코드는 하루에 한번 돌아가도록 되어있으므로 2023년11월25일부터 현재까지 해당되는 기간만큼 task가 실행된다는 소리다.
그래서 위 task를 나타내는 그래프 모양이 끝도없이 이어지는 것을 볼 수 있다.
이렇게 말이다ㅎㅎ;
기간을 잘 설정해서 실행하도록 하자.
4-2) ML Development 과정의 DAG 실습
이번에는 본격적으로 머신러닝을 활용한 dag 실습을 해 볼 차례이다.
[실습순서]
1단계 : dag 작성
2단계 : dag 실행
3단계 : dag 실행 결과 확인
feature engineering을 하고 이를 기반으로 traing을 진행해 볼 것이다.
training 방법은 random forest, gb를 기반으로 하고 둘 중에 성능이 좋은 모델을 선택하도록 구성해보자.
[경로]
경로는 기존의 docker 안에서 dags 폴더에서 시작한다.
[ml_development_dags.py]
vim ml_development_dags.py
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
from airflow.models import Variable
default_args = {
'owner': 'merona99',
'depends_on_past': False,
'start_date': datetime(2024, 11, 18),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'model_training_selection',
default_args=default_args,
description='A simple DAG for model training and selection',
schedule_interval=timedelta(days=1),
)
def feature_engineering(**kwargs):
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# XCom을 사용하여 데이터 저장
ti = kwargs['ti']
ti.xcom_push(key='X_train', value=X_train.to_json())
ti.xcom_push(key='X_test', value=X_test.to_json())
ti.xcom_push(key='y_train', value=y_train.to_json(orient='records'))
ti.xcom_push(key='y_test', value=y_test.to_json(orient='records'))
def train_model(model_name, **kwargs):
ti = kwargs['ti']
X_train = pd.read_json(ti.xcom_pull(key='X_train', task_ids='feature_engineering'))
X_test = pd.read_json(ti.xcom_pull(key='X_test', task_ids='feature_engineering'))
y_train = pd.read_json(ti.xcom_pull(key='y_train', task_ids='feature_engineering'), typ='series')
y_test = pd.read_json(ti.xcom_pull(key='y_test', task_ids='feature_engineering'), typ='series')
if model_name == 'RandomForest':
model = RandomForestClassifier()
elif model_name == 'GradientBoosting':
model = GradientBoostingClassifier()
else:
raise ValueError("Unsupported model: " + model_name)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
performance = accuracy_score(y_test, predictions)
ti.xcom_push(key=f'performance_{model_name}', value=performance)
def select_best_model(**kwargs):
ti = kwargs['ti']
rf_performance = ti.xcom_pull(key='performance_RandomForest', task_ids='train_rf')
gb_performance = ti.xcom_pull(key='performance_GradientBoosting', task_ids='train_gb')
best_model = 'RandomForest' if rf_performance > gb_performance else 'GradientBoosting'
print(f"Best model is {best_model} with performance {max(rf_performance, gb_performance)}")
return best_model
with dag:
t1 = PythonOperator(
task_id='feature_engineering',
python_callable=feature_engineering,
)
t2 = PythonOperator(
task_id='train_rf',
python_callable=train_model,
op_kwargs={'model_name': 'RandomForest'},
provide_context=True,
)
t3 = PythonOperator(
task_id='train_gb',
python_callable=train_model,
op_kwargs={'model_name': 'GradientBoosting'},
provide_context=True,
)
t4 = PythonOperator(
task_id='select_best_model',
python_callable=select_best_model,
provide_context=True,
)
t1 >> [t2, t3] >> t4
이렇게 코드를 작성해보았다.
dag를 만들기에 앞서서 다시 bash창에서 python코드 안에서 import했던 모듈을 pip명령어로 설치해주는 작업이 필요하다.
pip install pandas
pip install scikit-learn
이후
sync
한번 입력해준 후
airflow dags reserialize
reserialize를 진행해준다.
[airflow 서버]
성공적으로 dag가 생성되었다.
[Graph]
[dag 실행]
실행버튼을 눌러 실행해보자.
success가 잘 떨어졌다.
어제 날짜부터 시작하도록 했으니 총 두 번의 dag가 실행됬음을 옆의 막대그래프에서 쉽게 볼 수 있다.
[Logs]
select_best_model이라는 task의 log를 확인해보면
이렇게 두 모델 중 좋은 성능의 수치가 출력되는 것을 확인할 수 있다.
select_best_model의 코드내용은 아래와 같다.
이렇게해서 이번에 배운 dags를 적용해서 다수의 모델을 원할 때 간편하게 돌릴 수 있는 airflow를 맛보기로 살펴보았다.
속성으로 필요한 내용만 빠르게 배운 느낌이다.
추가적으로 상세한 내용은 구글링하면서 알아가면 될 것 같고, 기본적인 지식은 강의에서 다룬 것 같기에 프로젝트에 접목하기엔 무리는 없을 것 같다.
// 이전에 ai 프로젝트를 여러개 진행했을 때 모델의 성능을 위해서 계속 모델을 갈아끼우곤 했었다.

























댓글